10 Important Things to Improve ODI Integrations with Hyperion Planning Part 10 (1/2) (Generic Data Extract)
Hi guys, we are finally getting at the end of our series about important things to make your ODI integration with Hyperion Planning better, faster and smarter. Today we will talk about extract data from Essbase and because this topic involves a lot of how Essbase itself works, we decided to split it in two parts.
The first one we will talk about how Essbase works and what is the best (I mean faster) way to extract data from it. In the second part, we will show how we can create a dynamic interface using ODI and both of the fastest ways to extract data from yours cubes.
Well, this is the first hint: we will need to have two different approach for two different occasions, and for everybody understand why I am saying that, let us talk a little about how BSO cubes works.
I will not enter in too many details here because there are many excellent blogs that talks about Essbase, like the blogs of my friends Glenn and Cameron for example.
As everybody knows, a BSO cube works by blocks right? The block is based in the combination of the store members in the dense dimensions. This is what defines the size of the block. The amount of the block will be defined by the amount of sparse members in the outline.
A very common way to configure the density of the cube is to set the Account and Period dimension as Dense. Normally we do that because the majority of the calculations happens between periods and accounts members, and putting both inside a block makes Essbase uses his resources better since it needs to bring only one block to the memory and then do all the calculation that uses account and period. (Off course this is not true to all the cases and I have some examples of this)
OK, said that let us talk about the four ways to extract data from Essbase:
First, we have the Report Script. This one I do not have too much to say since it has the worst performance from the four ways. I can only say that you should not use it.
The second possible way is using the Essbase Java API. We will not discuss about this today because it is a little complex and needs some other programming skills (But do not worry, we will talk about it in a near future)
The third way is the old Calculation Script. This is one of the best and most flexible way to extract data from Essbase. It was the fastest way too until an undocumented command from MDX came up to the internet.
The forth one is the MDX. Basically this is the SQL language of Essbase. It is normally used to query ASO cubes but you can use it to query BSO cubes too. MDX is a very flexible language and offers a good way to get data from Essbase and it has some cool commands that Calculation script does not have. (Off course, the other way around is true too).
Ok, now that we had some briefing about the extraction method that we can use (ODI can use any of them as extracting engine) let us talk about which one is better.
I ran some tests with both, MDX and Calculation Script and I conclude some very interesting things: Both are the best and faster way to extract data for Essbase, but everything depending on what you want to extract.
First the cube:
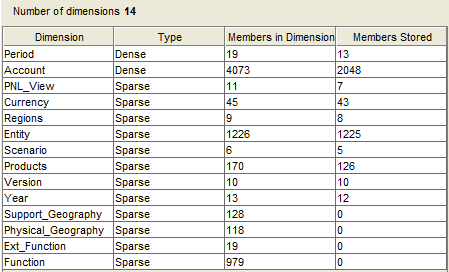 This is a pretty forward cube with Period and Account as Dense, 8 Sparse dimensions and 4 attribute dimensions.
This is a pretty forward cube with Period and Account as Dense, 8 Sparse dimensions and 4 attribute dimensions.
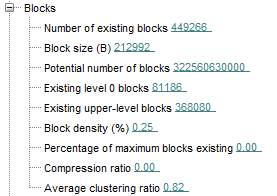 The block size has a decent size (This is a 64 bits Essbase) and we have 81186 level 0 blocks to play around.
The block size has a decent size (This is a 64 bits Essbase) and we have 81186 level 0 blocks to play around.
The CalcScript:
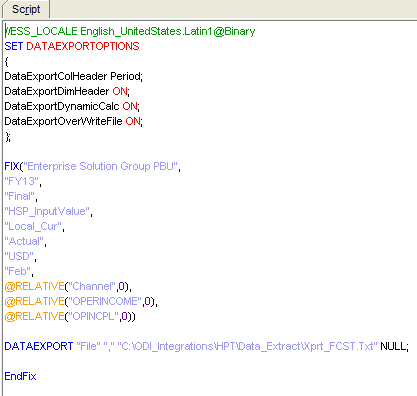 As we can see, this common CalcScript will extract some Lvl0 Accounts from February.
As we can see, this common CalcScript will extract some Lvl0 Accounts from February.
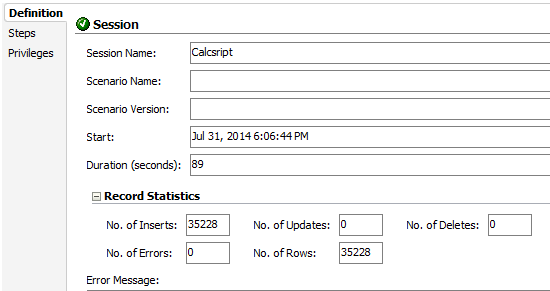
After build the CalcScript, we created a very simple ODI interface that uses this CalcScript to extract data. Basically what ODI does when you set a CalcScript as extraction engine is to execute the calculation script in Essbase server making it create a file. After the file is created, it loads the file into a table. The entire process took 89 sec and loaded 35228 rows (including missing blocks).
 Now lets see the difference when we use MDX. Same process, first I created a MDX and then I associated it into an ODI interface. This is the MDX:
Now lets see the difference when we use MDX. Same process, first I created a MDX and then I associated it into an ODI interface. This is the MDX:
 As I mentioned before, CalcScript was the fastest way to extract data from Essbase until an undocumented command appears in the internet. (I do not remember where I found it, but it was 3 years ago).
As I mentioned before, CalcScript was the fastest way to extract data from Essbase until an undocumented command appears in the internet. (I do not remember where I found it, but it was 3 years ago).
Anyway, the command is the NONEMPTYSUBSET. Well, how is it different from the NON EMPTY command? Well, the NON EMPTY will remove all empty members AFTER the query is executed and the NONEMPTYSUBSET will evaluate you subets of members BEFORE asking the data to Essbase and then will query it. This makes a huge difference, and this is what makes the MDX faster than CalcScript.
One important thing is that because of this pre evaluation of the Subsets, checking if the subset of members are empty or not, it is very important to create a big “Block” of members to use this command. This is why I used currency in the columns (Currency always has data but it could be periods too) and I created a nested Crossjoins to get all the other hierarchical dimensions. Everything else I put in the WHERE.
If you create a MDX using one axis for each dimension the NONEMPTYSUBSET will test that combination and if it’s empty it’ll bring no data. For example, in the query below the NONEMPTYSUBSET will first evaluate the combination of lvl0 of channel and account plus currency and everything that exists in the WHERE but not what is in the second NONEMPTYSUBSET. Of course, it will end into an empty “Block” of members.
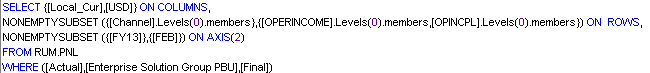 Resuming, you must have only one NONEMPTYSUBSET per query.
Resuming, you must have only one NONEMPTYSUBSET per query.
And the results? It’s true, the same query, almost same amount of rows (remember, it took off the missing) took only 21 seconds to be executed. This is more than 4 times faster than our CalcScript execution.
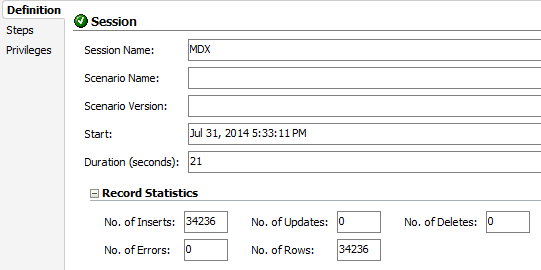 Ok, before Cameron ask me how this is different from what he wrote in his Post let me continue showing 2 more tests. What happens if you want to extract an entire year of data? Let me show you the results and then some explanations.
Ok, before Cameron ask me how this is different from what he wrote in his Post let me continue showing 2 more tests. What happens if you want to extract an entire year of data? Let me show you the results and then some explanations.
The CalcScript:
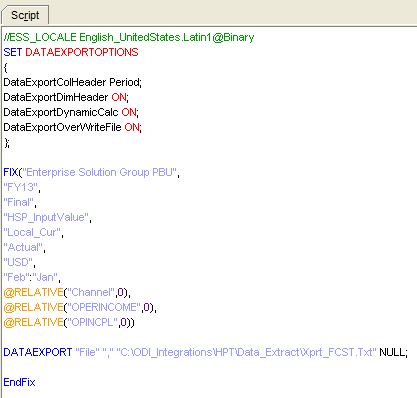 Same CalcScript from before but now I’m getting the Feb:Jan instead only Feb. The results:
Same CalcScript from before but now I’m getting the Feb:Jan instead only Feb. The results:
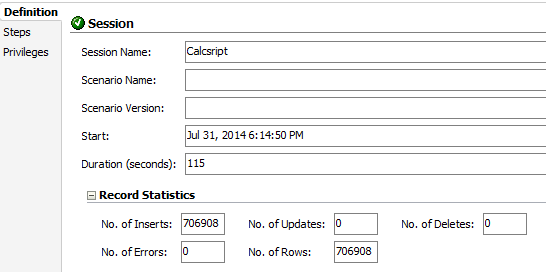 Did it extract 20 times more rows and took almost the same time? Indeed it did. In fact it was exactly the same time. Why you are asking? Because I am showing the overall execution time and you need to remember that first it extract to a file and then it loads the file to a table. In the first execution the “Insert new rows” step (this is the step that loads the file) took 0 seconds to be executed, and in the second execution, it took 13 seconds, giving us 102 sec for the CalcScript execution. If we remove the time to create the file too, the extract process took the same amount of time for a month or a year.
Did it extract 20 times more rows and took almost the same time? Indeed it did. In fact it was exactly the same time. Why you are asking? Because I am showing the overall execution time and you need to remember that first it extract to a file and then it loads the file to a table. In the first execution the “Insert new rows” step (this is the step that loads the file) took 0 seconds to be executed, and in the second execution, it took 13 seconds, giving us 102 sec for the CalcScript execution. If we remove the time to create the file too, the extract process took the same amount of time for a month or a year.
Well this was easily explained in the beginning of this post. Because we are extracting data from a BSO cube and the Period dimension is part of the block, for Essbase it is exactly the same to export one month or one year because it’ll bring the block to the memory and we’ll have all periods there.
In fact, in some cases it takes more time to export only one month than a year because for Essbase, filtering a month from the block is an extra step.
Really Interesting right? However, how do MDX behaves when we need it to extract a year of data?
Let us see. First the MDX:
 Same as before but now with [FEB]:[JAN], and the result is:
Same as before but now with [FEB]:[JAN], and the result is:
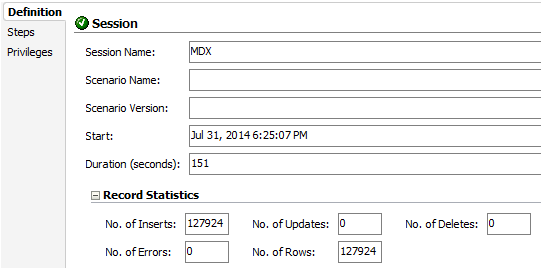 What? 151 seconds? Why is that? What is this number? Is this the 21 seconds for one month times 12 (12 months) plus the time to load to the table? You bet. MDX does not handle the block in the same way that CalcScript does. Maybe this is explained by the fact that MDX was born to query ASO cubes.
What? 151 seconds? Why is that? What is this number? Is this the 21 seconds for one month times 12 (12 months) plus the time to load to the table? You bet. MDX does not handle the block in the same way that CalcScript does. Maybe this is explained by the fact that MDX was born to query ASO cubes.
I do not know the reason but what I do know is that, if you need to extract an entire year and your Period dimension is inside the block, probably the best way will be using CalcScript. I said probably because CalcScripts are specially vulnerable regarding the design of the cube. I mean, everything counts, the size of the block, how dense is the block and so on.
In some cases I saw a huge difference in both, calculating and extracting data using CalcScript, if the cube is closer to 100% dense and if it is not. In addition, for extracting data I found that extremely small blocks make the process extremely faster, and when I say small blocks, I mean only periods as dense. Off course, making the block this small will impact in the calculation (you will need to re-think your formulas, the storage settings in the account dimension, caches and other things), but the extract will be extremely fast.
Anyway, my point is that depending on density, block size, settings, cube design, weather and some other stuff, the behavior of the cube could and probably will change, making the choice harder. But at least we know that we have two very good approaches and that depending of the data that you will need to extract, we will have one choice in mind.
In the next blog we will show you how to handle both methods using ODI and how to make the interface dynamically extract data from any number of cubes with any possible design.
I hope you enjoy this post see you next time.

August 22, 2014 at 1:17 am
Hey!
Thanks very much for this! It matches very closely the output I was seeing recently in some testing I did.
http://www.network54.com/Forum/58296/thread/1407912207/MDX+Optimisation+of+Crossjoins
At the time, I’d thought that I was simply hitting the memory limits of crossjoins (I had some big dimensions to play in). But in my testing (even with Cameron’s ‘cheating’ NONEMPTYBLOCK statement), once I was querying past a certain point MDX got significantly slower than dataexports for the same dataset.
Cheers
Pete
August 22, 2014 at 10:32 am
Hello Peter how are you? You know, the difficulty to right anything related with calculation script or MDX is that everything counts. Sometimes the MDX is slower than calc script no matter what and sometimes is the other way. Everything depends of everything and the only solution is testing. But yes the MDX is very good for one month (it resolves faster the “Fix” inside the block) and the other advantage is that the API uses the MDX as POV and get the data directly from essbase, it not create any file (as calcscript, that some times take a while to load becase network and file performance itself). But in general it’s a good pratice to use MDX to a month and CalcScript to a “block”. At least is what I found this far.
Thank you.
December 13, 2017 at 4:21 am
Hmmm it seems like your blog ate my first comment (it
was extremeloy long) so I guess I’ll just sum
it up what I submiitted and say, I’m thoroughly enjoying your blog.
I ttoo am an aspiring blog blogger but I’m still new to everything.
Do you have any recommendations for rooke blog
writers? I’d genuinely appreciate it.
December 13, 2017 at 8:06 am
Hi, how are you? That was my fault! I thought I had approved your comment but for some reason I didn’t…. I’m really sorry for that…
About your question, start a blog is not the hard part, to keep it going it is…. With time you get a little more used with writing (at the beginning everything takes a lot of time to write..).
What we did was, we create a series of posts (10 things to improve….), because in this way I we ware sure that we would continue to write for a while (at least until we finish our series).
And this paid off because it took a while to write everything, we get used with writing (kind off :)) and we start to see the fruits of our labor…. and enjoy it.
Now, we still fight to produce material… we like to write about solutions (and this demand more then just a few words and is not everyday we have something), and its something we are trying to change. I think we need a balance between big and deep posts and simple tips posts….
Anyway, I hope you start to post and I hope this insights help you a little bit :). A blog takes some of your time, some time is a pain (because you need to keep posting but you don’t have time) but for sure is gratifying.
Thanks and have a great day!