Hi all, as mentioned in the second post of this series, there is a faster way to load data into Snowflake using ODI. It will require the creation of new KM, it has some peculiarities that some may think as limitations at first but the speed of the data loading is totally worth the work and the preparations needed for making it work. First, lets just picture how is the current Snowflake JDBC process.
It’s simple and very straight forward. You create an ODI mapping that will read your on-premises DB and send data over to Snowflake using JDBC. If you have small data loads or if you are happy with the time that the jobs are taking using this method, I recommend you stay with it because its pretty simple and works.
Now, if you need speed due to the volume of data that you need to transfer, you may create the following architecture:
Let’s describe the steps. First ODI will be used (using a Mapping) to generate a text file. The format may be anything you like (it needs to match the Snowflake stage definition, as you will see below). I’m using a pipe | delimited file for this example. Then ODI calls SnowSQL client (more on that later) that will compress and push the file to a Snowflake STAGE area, which will then be finally copied over to the final table.
If you stop and think a little bit about it for a second now, it seems very stupid. You have the data in a database, you extract it to a file, then you call a process to compress/push over the internet, stage it then finally copies it. Its way more work than the first method, right? It is way more work, it also requires space to store the text file, however, its way faster then JDBC.
You see, the main bottleneck when working with the cloud is exactly the transfer over the internet. With the second technique, what we end up doing is to zip a large file and send it across the network all at once, instead of relaying in a Java JDBC connector that is buffering some X number of rows and sending it across repeatedly. The amount of work that the JDBC driver does internally is way more and way slower than just creating a file, compress it, send it.
Also, cloud structures are awesome on working with files. Every cloud provider out there makes it very easy and fast to manipulate “raw” data. Snowflake is no different. It will stage and copy the compressed text file in an extreme speed, way faster then batch of rows using JDBC.
If you are still not sure if you should follow this route, my answer is wait until you really need to create a fast process and give it a go. You may do a test by simply extracting the data to a text file and run SnowSQL commands to push the data. You will see it will be super-fast.
Let’s see how we should implement this. First thing is that you will need to install SnowSQL client on your architecture (ODI agent server). This client will be the one called to execute things in Snowflake, including pushing the file and copying it. I won’t go over the details on SnowSQL, but you may read it all in this documentation from Snowflake.
Another thing that I’ll just assume that you know is how STAGES, PUT and COPY commands work in Snowflake. You may read about their documentation here, here and here.
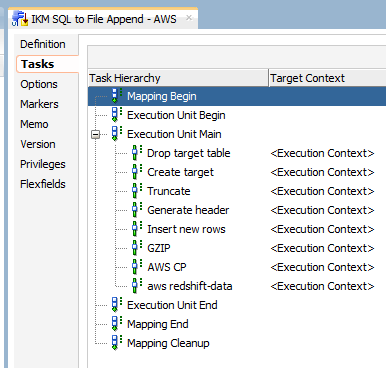
Second step is to create a copy of the current “IKM SQL to File Append” and give it a new name, in my case its “IKM SQL to File Append – Snowflake PUT”. Delete some steps of it and leave only the ones below:
These ones will basically just create a file in a server. This file needs to have the same name as the table that you will want to load in Snowflake, plus the “.txt” extension (e.g., if you are loading CLIENTS table, you need to create CLIENTS.txt file in the server). The target Datastore definition may be anything you want, but I’m following this pattern:
Now you need to add only two more steps in the KM, as below:
Snowflake PUT
The target command is the following:
OdiOSCommand "-OUT_FILE=<%=odiRef.getTable("TARG_NAME")%>_put.log" "-ERR_FILE=<%=odiRef.getTable("TARG_NAME")%>_put.err"
snowsql -c #P_CONNECTION_NAME -w #P_SNOW_WAREHOUSE -r #P_SNOW_ROLE -d #P_SNOW_DATABASE -s #P_SNOW_SCHEMA -q 'PUT file://<%=odiRef.getTable("TARG_NAME")%>.txt @#P_STAGE_NAME auto_compress=#P_AUTO_COMPRESS parallel=#P_PUT_PARALLEL'
We can see that it is basically one OS command that is calling snowsql client. It is passing all the connection information in order to login and then it is issuing a PUT command to Snowflake. This PUT command is sending a text file to a stage area, with auto compress and a defined number of parallel workers. If you are familiar with ODI, you know that all of those # variables need to come from some place. You may implement in any way you want, but in my case, I did put a SQL statement in the command on source tab that returns all this information from a parameter table that is located in the on-premises database, like below:
I even added a CONFIG_CODE filter (which is a KM option that I added to this new KM), in the case of having multiple Snowflake configurations (which is very common to have). So, if you have multiple configs, you may add this option on your new KM and use it when you are creating a new mapping.
Snowflake Copy
This step is very similar to the one before. In the target tab we will have the following:
OdiOSCommand "-OUT_FILE=<%=odiRef.getTable("TARG_NAME")%>_copy.log" "-ERR_FILE=<%=odiRef.getTable("TARG_NAME")%>_copy.err"
snowsql -c #P_CONNECTION_NAME -w #P_SNOW_WAREHOUSE -r #P_SNOW_ROLE -d #P_SNOW_DATABASE -s #P_SNOW_SCHEMA -q 'copy into #P_SNOW_DATABASE.#P_SNOW_SCHEMA.<%=odiRef.getTargetTable("TABLE_NAME")%> from @#P_STAGE_NAME/<%=odiRef.getTargetTable("TABLE_NAME")%>.txt.gz'
This one is issuing a copy from Snowflake stage to the final table. On the source tab, we have the same SQL shown on the prior step:
And that’s it. You are ready to push data from on-premises to Snowflake in a very fast way. It gives you some work upfront, but I may guarantee to you that it’s worth it.
Thanks, see you soon!