Continuing our Oracle SQL for EPM series, today we’ll start to talk about analytic functions and how can we use them for more than “just” analytics.
To start with, let’s talk about RANK(). As the name suggest, RANK() is used to rank our data based in something. It’s very useful to find out each data is more relevant than others. Let’s see a example:

Here we have a small table with 2 currencies and a few products. Let’s first start with the basic function of RANK() and see each product generated more income:

The basic syntax is RANK() OVER (ORDER BY COLUMN). Basically what you are saying to oracle is, rank my data based by a column (or multiple columns). Since I just ordered by data, the values of the RANK() got duplicated everything oracle finds the same value. This is because we have 2 currencies and they are both USD.
To fix data we can do 2 things: Or we can include currency in side the order by or we can use another more advanced use of RANK() that is OVER PARTITION.
Let’s see how it works:
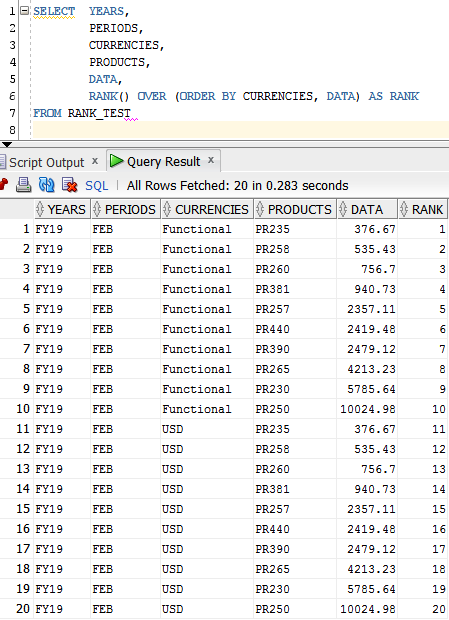
If I just add another column in the ORDER BY, it’ll basically create the Rank based in the order of these 2 columns. It’s the same as do a ORDER BY and then follow the order of the data that returns. Then in this case, you can see that the products PR235 for Functional Data got Rank 1 and for USD rank 11, even both having the same value. By the way, you also can see that the Ranks is ordering in the opposite order that we would like to have. This was intentional to show you how the Rank is produce. To fix that we just need to put a DESC in the ORDER BY clause, like we would do in a normal ORDER BY.

Ok then let’s see the more advanced way to write this query:

Instead of inserting new columns in the ORDER BY we can use PARTITION BY instead. The results here is the same, but this can be used in other ways as well and I would say that this would be the best way to used it since is more clear what you want to do.
The PARTITION BY does exactly what the name says, it partition the data by the content of one or more columns. In fact, the PARTITION BY clause can be used in most off the analytics functions like MAX, SUM, MIN, AVG…. then it’s very powerful and the best thing is that, if you use it, you don’t need to use a group by (we’ll see that in the future).
Now, as I said before, we can have other uses for RANK than just ranking data. Let’s say that you have this table without the CURRENCIES column:

Without the CURRENCIES column we end up with duplicate data in the table right? In this case we could do just a distinct and use the data as is, but let’s say you want to create the CURRENCIES column based in the data that we have, and the rule would be, the first data you find is USD and the second (if exists) would be Function. We can use Rank for that too:

Since here the data is the same for the same product, the only thing that could differentiate them was the ROWNUM (or ROWID, that would be better to make sure each one was the first one, but harder to see the example) I used it to create a Rank that shows each row has the lowest ROWNUM and that would have the Rank 1, the second one will be 2 and with this information, I just did a decode to make the 1 USD and the 2 Functional (Also a NA in case we have more than 2 duplicated rows).
This can be used in exactly the same way if you have a metadata table without the datastorage information and you want to create it. Then the first member you find (Trough our friend CONNECT BY PRIOR) will be the Prototype (Store or never Share or Dynamic Calc and Store) and the other would be Shared members.
Of coarse there’s way more ways to use this function, and we’ll see more of them with the other analytics functions that we’ll going to see here.
See you soon guys.




























