Hi all!
This post is based in one question that I answered in the Data Integration community forum some time back. This feature is powerful, but it is also somehow “hidden”. The question was like this (I have edited it for the purpose of this post):
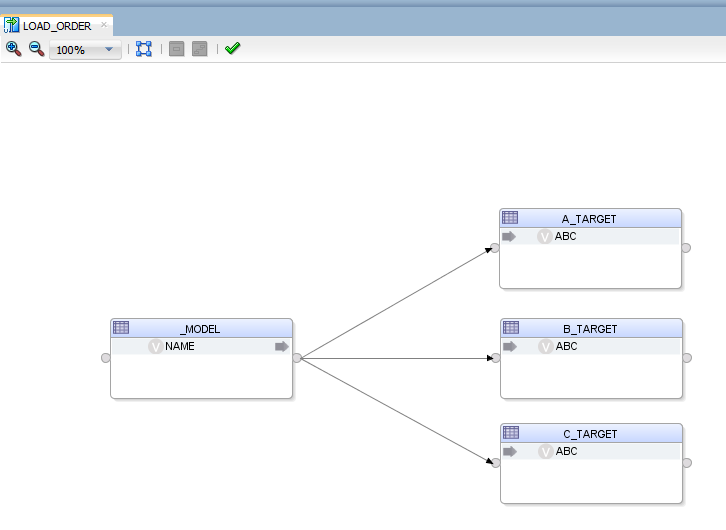
I have one mapping that will load one target table (TARGET) from two different sources (SOURCE_A and SOURCE_B). Target table TARGET contains ITEM_KEY, ATT1, ATT2, ATT3 and so on. One Source (SOURCE_A) contains ITEM_ID, ATT1, ATT2, ATT3 values and we are using a look up to a dimension table (T_ITEM) to get ITEM_KEY for the ITEM_ID. Second source (SOURCE_B) contains CC_ID, ATT1, ATT2, ATT3 and there is a reference table (T_CC_ITEM_REF) which contains the mapping between CC_ID and ITEM_ID that we use to look up to the dimension table (T_ITEM) to get ITEM_KEY for the ITEM_ID.
Validating the first source is straight forward as we have declared a constraint in CKM to log foreign key error records which got logged as ‘Join Error between TARGET and T_ITEM’ in E$. For the second source, there is a “middle” table in the mapping, so we must join SOURCE_B to T_CC_ITEM_REF (reference table) and to T_ITEM (dimension table). I can still create a constraint and log foreign key errors between TARGET and T_ITEM, but is there a way that I can also be more specific and capture any join error between T_CC_ITEM_REF (reference table) & T_ITEM (dimension table). E.g. if T_CC_ITEM_REF is missing any mapping record or if any mapping is mapped to an inexistent T_ITEM row?
This is very good example of “indirect join” validation, where you want to validate some source data that is used in your mappings, but these tables are not directly associated with your target table. In these cases you cannot directly validate them in a regular mapping, but ODI has a very nice feature called Static validation, which allows you to run any validation in any data model at any time, so you could catch all those errors before trying to load your target table.
If you go to ODI models and expand any of them, you will see that you may add “Constraints” to it. Generally, we add those constraints to the target table, so data gets validated during the load data flow, before hitting the actual target table. I said “generally” it is done in the target because we have situations (like the one that we are talking now) where we want to validate the source/mapping tables even before we try to load the targets.
Before getting directly on how to solve this issue, lets step back and briefly see some options that ODI has to offer regarding data validation. If you go to ODI models and expand any of them, you will see that you may add “Constraints” to it.
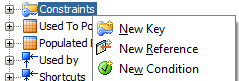
The first one is a “Key”, which resembles a “Primary Key”. You will add all columns that belongs to your table primary key and ODI will make sure to log all records that are not unique based on this key.
The second one is “Reference”, which resembles a “Foreign Key”. You will add the columns and tables names that belongs to a foreign key relationship and ODI will automatically log all records that have no reference between that relationship. If we go back to the above question, this works fine to validate our TARGET table against the T_ITEM (dimension) because there is a direct link between them. ODI will log all source rows that does not have a valid “join” to the T_ITEM table before loading it to the target (so the target has only “valid” records regarding that FK).
Third one is called “Condition” and it is the most flexible of all ODI constraints. Basically, it is a free form text where you may add any kind of SQL statement which you want to check. You just need to remember that you always want to write down a statement that will check for TRUE values, as for example, you want to test if a column value exists, “is in” another table or if the values are greater or lesser than a specific value. When you execute your mapping, you will see that ODI will “negate” your condition adding a NOT before it, so it will check for all the records that are not TRUE (in other words, FALSE) and logging them at the E$ table. Pretty neat stuff.
Going back to our example, let’s divide our problem in two pieces. First let’s validate if T_CC_ITEM_REF contains any kind of bad data, meaning that we will check if it contains any mapping row that references a non-existing T_ITEM row. This can be achieved by going to T_CC_ITEM_REF and create a New Reference.
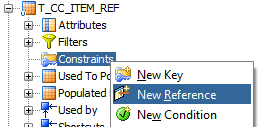
There you point the “Parent Table” (in this case, T_ITEM):
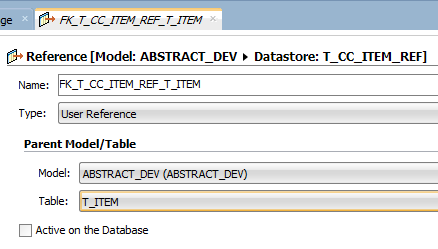
In attributes, add the two columns that are used in the join condition:

Save it. Go to the parent Model of this datastore and check its Control tab. You will need to select which CKM will be used to run the Static validation (you cannot leave it blank).
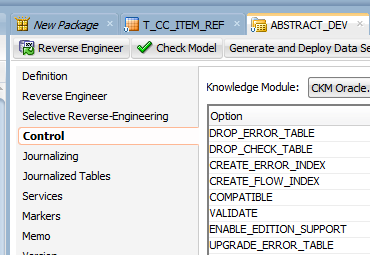
Create a new package and “drag and drop” the model to the package. It will look like this:

This icon indicates that, once you run the package, ODI will run a Static validation on this datastore using the CKM that we set in its parent Model. Once we run it, this is what we get in Operator:

The warning sign on the scenario execution tell us that some error was logged in the E$ table. When we go to check it, we can see following:

It means that ITEM_ID 50 does not exist in T_ITEM, so any source record with CC_ID equals to 5 would be dropped due to an invalid mapping row.
Now, what if we want to check if all CC_IDs from the source has a valid mapping record? This is where “Condition” constraint comes in handy, since it is very flexible and allow us to virtually write any kind of SQL logic in it. Let’s go to SOURCE_B and create a Condition to it:

Add a name to it and select a type. An Oracle Data Integrator Condition is a condition that exists only in the model and does not exist in the database. A Database Condition is a condition that is defined in the database and has been reverse-engineered. In our case, let’s pick ODI Condition. Write the SQL statement that you want to be true. In this case, I want all source CC_ID columns to be not null and that also exists in the join between my mapping/dimension tables. Another cool thing about conditions is that you may write custom messages for it, so it gets clearer to the users what that validation means.
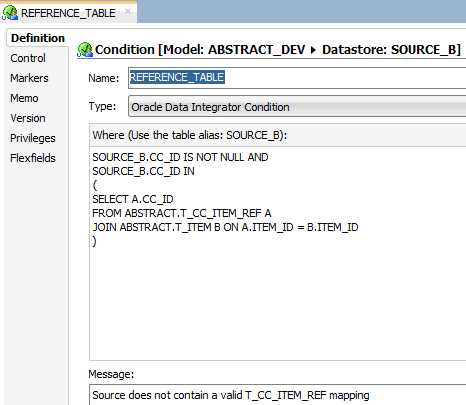
Similarly, to the previous example, drag and drop the model to the package and run it. This is what you will get:


The error is telling us that there is a source record (CC_ID 3) that does not have a mapping record on T_CC_ITEM_REF. You may add both Static validations on your package, before you load your target and have a complete picture on what data is missing in your data flow.
Hope you have liked the post. See ya!