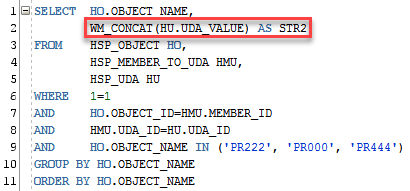
Hey guys how are you? Let’s take a look today in the opposite of S01EP12 situation, in fact we’ll use the same example again to show how can we convert a string in a list of values in a easy and dynamic way, starting with this query here:

I’ll transform this query in a with and I’ll use REGEXP to put this back into a list of values. This is very useful when we extract metadata from essbase for example, because essbase exports the UDA’s as a list of values. Of coarse this has many uses other than this but let’s keep this one in mind.
Now what we need to do is to split the strings by comma in this case, then the idea is to count the amount of commas we have in a row and split the strings by that amount.

The idea here is to use the REGEXP_COUNT to count how many words we have in between the commas and then use it to multiply the rows in the CONNECT BY LEVEL. For example, if we have 3 words, the connect by will create 3 rows of the same row, one with the LEVEL = 1 another with the LEVEL =2 and the last one with LEVEL=3.
With that we just need to use the REGEXP_SUBSTR to extract the words based in the LEVEL, this way we’ll have the REGEXP_SUBSTR(STR, ‘[^,]+’, 1, LEVEL (that will be 1 for the first row, 2 for the second and 3 for the third one).
I hope this can be useful and see you soon.