Hey guys how are you?
Today I’ll going to show you how to “Save As” an essbase outline using ODI and Java. I normally use Maxl and OS commands to do this kind of things but turns out, there’s no Maxl to do that.
In fact, this is very interesting even if you don’t like java, because it’ll show exactly what Essbase does behind the scenes to save a outline. Let’s start.
First of all we’ll going to need some essbase API libraries. In ODI, the Client and the Agent already include some Essbase Jars in the Lib folder (one Lib folder for the Client and one for the Agent).
If you need anything outside what you have there you need to copy from essbase to the Lib folders and restart the agent. In this case we’ll need to import these:
import com.essbase.api.base.EssException;
import com.essbase.api.datasource.IEssCube;
import com.essbase.api.datasource.IEssOlapFileObject;
import com.essbase.api.datasource.IEssOlapServer;
import com.essbase.api.domain.IEssDomain;
import com.essbase.api.metadata.IEssCubeOutline;
import com.essbase.api.session.IEssbase;
After that we need to create a few String variables to help us organize our code:
String s_userName = <%=odiRef.getInfo("SRC_USER_NAME")%>;
String s_password = <%=odiRef.getInfo("SRC_PASS")%>;
String olapSvrName = <%=odiRef.getInfo("SRC_DSERV_NAME")%>;
String s_provider = "Embedded";
String appNameFrom = "Juno_M";
String appNameTo = "Juno";
String database = "Analysis";
IEssbase ess = null;
IEssOlapServer olapSvr = null;
Since I’m using an ODI procedure, I can set in the Command on Source tab the Essbase connection I want and then I can get in the Command on Target the User name, password and the server name as well, using the ODI substitution API, this way I can use what is store in the Topology without to worry about hard-code any password in the code.

In the next step we need to connect in Essbase using:
ess = IEssbase.Home.create(IEssbase.JAPI_VERSION);
IEssDomain dom = ess.signOn(s_userName, s_password, false, null, s_provider);
olapSvr = dom.getOlapServer(olapSvrName);
olapSvr.connect();
Basically what this is doing is to instantiate and essbase server, connection in the domain using the Command on Source information and then connect into a specific Olap server. After this we are ready to start execute some commands. And now it gets interesting. This is exactly what essbase does behind the scenes:
- It Locks the Outline we want to copy:
- olapSvr.lockOlapFileObject(appNameTo, database, IEssOlapFileObject.TYPE_OUTLINE, database);
- It does an OS File copy from the source app folder to the target app folder:
- olapSvr.copyOlapFileObjectToServer(appNameTo, database, IEssOlapFileObject.TYPE_OUTLINE, database,”\\server\D$\path”+”\”+appNameFrom+”\”+database+”\”+database+”.otl”,true);
- As you can see, the command ask for the name of the app you want to save the outline, the type of the object (that is OUTLINE), the folder path for the source Outline and the last parameter is a true or false to tell if we want to unlock the object or to lock. True is unlock
- If you look into the target folder during this step, you’ll see that Essbase will copy the source .otl to the target folder as .otn
- Then we need to open the target outline using:
- IEssCubeOutline otl = olapSvr.getApplication(appNameTo).getCube(database).getOutline();
- otl.open();
- Last thing you need to do is to merge the .otn into the .otl files:
- otl.restructureCube(IEssCube.EEssRestructureOption.KEEP_ALL_DATA);
- otl.close();
- We just need to ask for the cube to restructure and pass the option KEEP_ALL_DATA, after that we can close the outline
Interesting thing here is that if you get a outline, rename to .otn, put this file inside a folder and force the cube to restructure (via EAS), it’ll automatically merge the created .otn with the .otl.
Also, this is why oracle recommend to have double the size of the cube in memory, because when we do a restructure, we have 2 outlines open at same time, the .otn and the .otl.
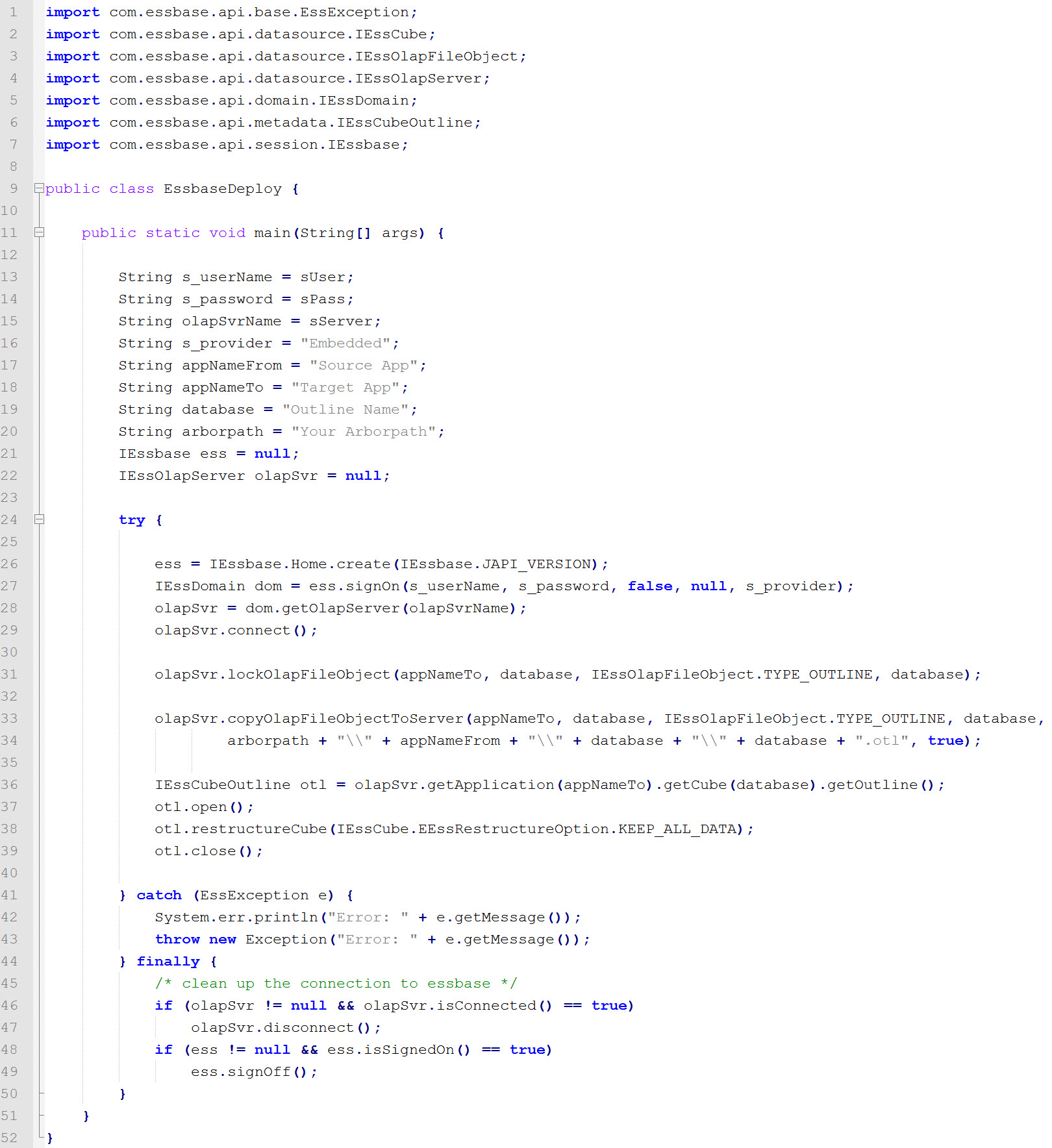
Here’s the entire code:
import com.essbase.api.base.EssException;
import com.essbase.api.datasource.IEssCube;
import com.essbase.api.datasource.IEssOlapFileObject;
import com.essbase.api.datasource.IEssOlapServer;
import com.essbase.api.domain.IEssDomain;
import com.essbase.api.metadata.IEssCubeOutline;
import com.essbase.api.session.IEssbase;
String s_userName = <%=odiRef.getInfo("SRC_USER_NAME")%>;
String s_password = <%=odiRef.getInfo("SRC_PASS")%>;
String olapSvrName = <%=odiRef.getInfo("SRC_DSERV_NAME")%>;
String s_provider = "Embedded";
String appNameFrom = "Juno_M";
String appNameTo = "Juno";
String database = "Analysis";
IEssbase ess = null;
IEssOlapServer olapSvr = null;
try {
ess = IEssbase.Home.create(IEssbase.JAPI_VERSION);
IEssDomain dom = ess.signOn(s_userName, s_password, false, null, s_provider);
olapSvr = dom.getOlapServer(olapSvrName);
olapSvr.connect();
olapSvr.lockOlapFileObject(appNameTo, database, IEssOlapFileObject.TYPE_OUTLINE, database);
olapSvr.copyOlapFileObjectToServer(appNameTo, database, IEssOlapFileObject.TYPE_OUTLINE, database, "#ESSBEXTRACT_FOLDER"+"\\"+appNameFrom+"\\"+database+"\\"+database+".otl",true);
IEssCubeOutline otl = olapSvr.getApplication(appNameTo).getCube(database).getOutline();
otl.open();
otl.restructureCube(IEssCube.EEssRestructureOption.KEEP_ALL_DATA);
otl.close();
}
catch (EssException e)
{
System.err.println("Error: " + e.getMessage());
throw new Exception("Error: " + e.getMessage());
}
finally
{
/* clean up the connection to essbase */
if (olapSvr != null && olapSvr.isConnected() == true)
olapSvr.disconnect();
if (ess != null && ess.isSignedOn() == true)
ess.signOff();
}I hope you guys enjoy this one and see you soon.