Hi all, today’s gem is something extremely useful that I’ve being using in every single project that I work on. Today’s gem is about SNP tables, which are the database tables that are used by ODI to store its metadata. When we install ODI, the installer asks us where we want to create our Master and Work repositories. Each repository contains a set of tables with different kind of information. From Oracle documentation:
- Master Repository: This is a data structure containing information on the topology of the company’s IT resources, on security and on version management of projects and data models. This repository is stored on a relational database accessible in client/server mode from the different Oracle Data Integrator modules.
- Work Repository: This is a data structure containing information about data models, projects, and their use. This repository is stored on a relational database accessible in client/server mode from the different Oracle Data Integrator modules.
You may think of them being the place where contains all information about the code that was developed in ODI, all the jobs that were executed, all the source and target tables and so on. These tables may give us answers to questions like: how many mapping objects does project X have? Which are the target mappings for a specific job? How many jobs are executing in a daily basis, how long does each of them take and how much data do they manipulate (insert/delete/update)? All those questions will eventually come to you after some time, and querying the SNP tables will provide you all the answers on what is going on in your ODI projects.
Below is one example of a query that returns a lot of information regarding all the ODI executions that happened in an ODI repository in a give time frame. It gives you the name of the scenarios, versions, when it began and ended, the session status, the order that they happened and (maybe the most important) which code was executed. The last info, together with how much time it took to execute, may be very useful to analyze which are the steps that are taking longer in your environment and then do something about them.
I wont go over each table and what they mean, but you may take a look on “Doc ID 1903225.1 : Oracle Data Integrator 11g and 12c Repository Description” in Oracle support for a full list of tables and their description. In the beginning, the number of tables and attributes may look intimidating, but once you start to use them you will see that the data architechture is fairly simple and you may retrieve a lot of good information out of them.
Without further due, here is the SQL. This one was created over ODI 12.2.1. Please notice that each ODI version may have changes in the repositories tables, which may lead you to modify those queries accordingly.
SELECT
SS.SESS_NO,
SS.SCEN_NAME,
SS.SCEN_VERSION,
SS.SESS_NAME,
SS.PARENT_SESS_NO,
SS.SESS_BEG,
SS.SESS_END,
SS.SESS_STATUS,
DECODE(SS.SESS_STATUS,'D','Done','E','Error','M','Warning','Q','Queued','R','Running','W','Waiting',SS.SESS_STATUS) AS SESS_STATUS_DESC,
SSL.NNO,
SSTL.NB_RUN,
SST.TASK_TYPE,
DECODE(SST.TASK_TYPE,'C','Loading','J','Mapping','S','Procedure','V','Variable',SST.TASK_TYPE) AS TASK_TYPE_DESC,
SST.EXE_CHANNEL,
DECODE(SST.EXE_CHANNEL,'B','Oracle Data Integrator Scripting','C','Oracle Data Integrator Connector','J','JDBC','O','Operating System'
,'Q','Queue','S','Oracle Data Integrator Command','T','Topic','U','XML Topic',SST.EXE_CHANNEL) AS EXE_CHANNEL_DESC,
SSTL.SCEN_TASK_NO,
SST.PAR_SCEN_TASK_NO,
SST.TASK_NAME1,
SST.TASK_NAME2,
SST.TASK_NAME3,
SSTL.TASK_DUR,
SSTL.NB_ROW,
SSTL.NB_INS,
SSTL.NB_UPD,
SSTL.NB_DEL,
SSTL.NB_ERR,
SSS.LSCHEMA_NAME
|| '.'
|| SSS.RES_NAME AS TARGET_TABLE,
CASE
WHEN SST.COL_TECH_INT_NAME IS NOT NULL
AND SST.COL_LSCHEMA_NAME IS NOT NULL THEN SST.COL_TECH_INT_NAME
|| '.'
|| SST.COL_LSCHEMA_NAME
ELSE NULL
END AS TARGET_SCHEMA,
SSTL.DEF_TXT AS TARGET_COMMAND,
CASE
WHEN SST.DEF_TECH_INT_NAME IS NOT NULL
AND SST.DEF_LSCHEMA_NAME IS NOT NULL THEN SST.DEF_TECH_INT_NAME
|| '.'
|| SST.DEF_LSCHEMA_NAME
ELSE NULL
END AS SOURCE_SCHEMA,
SSTL.COL_TXT AS SOURCE_COMMAND
FROM
SNP_SESSION SS
INNER JOIN SNP_STEP_LOG SSL ON SS.SESS_NO = SSL.SESS_NO
INNER JOIN SNP_SESS_TASK_LOG SSTL ON SS.SESS_NO = SSTL.SESS_NO
INNER JOIN SNP_SB_TASK SST ON SSTL.SB_NO = SST.SB_NO
AND SSTL.SCEN_TASK_NO = SST.SCEN_TASK_NO
AND SSL.NNO = SSTL.NNO
AND SSTL.NNO = SST.NNO
AND SSL.NB_RUN = SSTL.NB_RUN
LEFT JOIN SNP_SB_STEP SSS ON SST.SB_NO = SSS.SB_NO
AND SST.NNO = SSS.NNO
WHERE
SS.SESS_BEG >= TRUNC(SYSDATE) - 1
ORDER BY
SESS_NO,
NNO,
SCEN_TASK_NO
See ya!























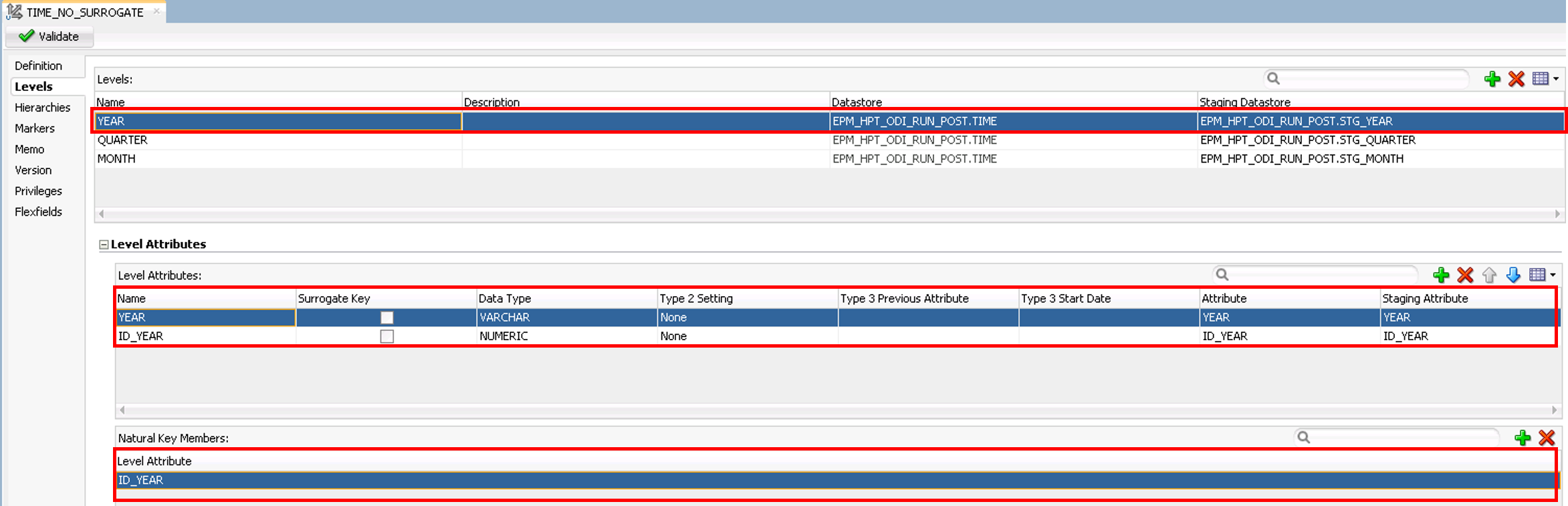
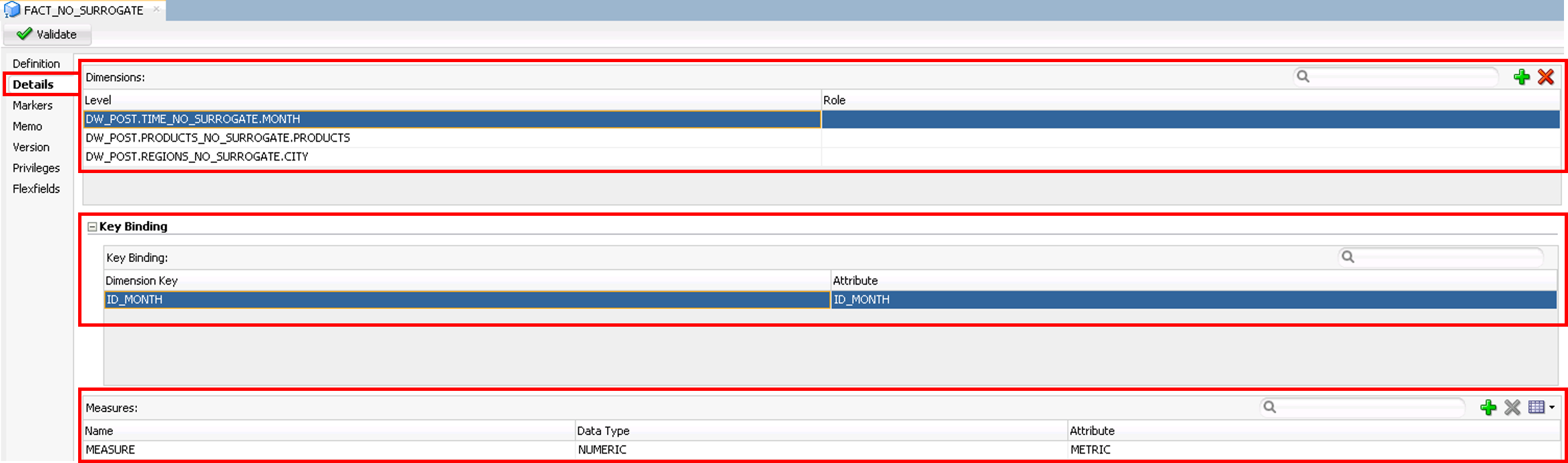
 button will create a Level.
button will create a Level.