Hey guys how are you? Today I’ll talk a little bit how can we create a dynamic HTML table email from ODI using Jython.
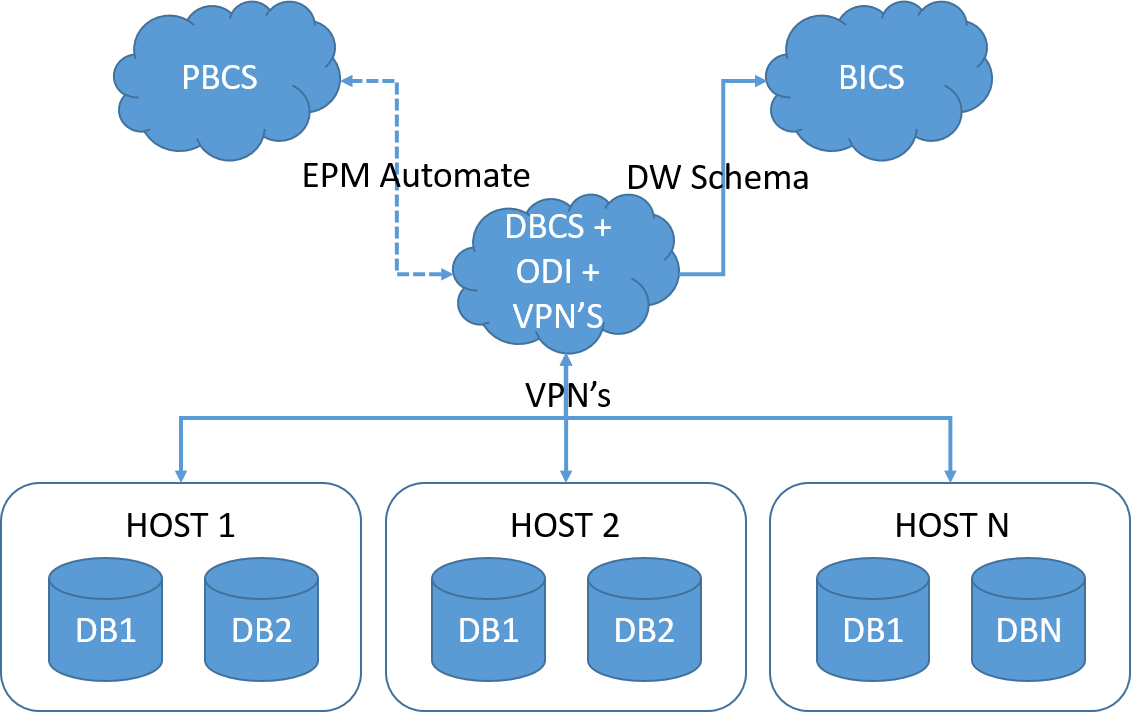
First of all, let me give you a little bit of context. I had to build an ODI process to restate the past data in our DW. That means, the business wanted, to a certain point in time, to go back all the way to the first period we have in our DW and restate the data based in a map table that they provided.
That’s all right, the biggest problem is that this table is partitioned by Source System and Period, and the business wanted the process to be flexible enough to let them run 1 period and 1 source system at time or to run an range of period and ALL sources at time (and any combination of these 2).
Also all right, my problem now is how to provide the business with a reliable way to tell them what they already run, what is still pending, if we had an error in a period or if there’s some validation fall outs in a period. In other words, how to track the process during execution.
My answer to that, I decide to send a email with a table that shows the source system and years in the rows and the months in the columns, and based in a color code, I paint the cells based in the status of the execution.
This post will be about the Jython/HTML code we wrote and the next post will be about how to make it dynamic in ODI. Let’s start it with the Jython part:
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
mailFrom = "ODI Services <donotreply@ODI.com>"
mailSend = 'email@here.com'
msg = MIMEMultipart()
msg['Subject'] = "Subject here"
msg['From'] = mailFrom
msg['To'] = mailSend
html =
"""\
HTML CODE HERE
"""
part = MIMEText(html, 'html')
msg.attach(part)
s = smtplib.SMTP('SMTP SERVER HERE')
s.sendmail(mailFrom, mailSend.split(','), msg.as_string())
s.quit()
This is everything you need to have in your procedure to send a HTML code by email. It’s a very simple code, basically we import “smtplib” lib and that will handle the email sending, after that we just need to inform the user, password and SMTP server and use the “sendmail” to send the email. Pretty straight forward.
Now, in the meddle of the code, we have the HTML part that needs to be included. In our case, it’ll be a table. To test the HTML code, you can google “HTML test runner” that it’ll bring a lot of places in the internet where you can run your HTML code and test to see the results. It’s pretty handy, and I’m using this one here.
To create a simple table in HTML we just need this code here:

This code is also fairly simple and basically we have:
- <TABLE> tag, where you define the margins, border size, width of the table, cell padding and cell spacing. There’s more options there but you can easily find in the HTML doc.
- <TR> tag, where you define the amount of columns using the COLSPAN property as well the alignment of the text there
- <TH> tag, where we define the cells of our table itself. There’re a lot of properties for this but I’m using juts a fix 20% width for each cell, just to size them the same (since I have 5 columns), the Color of the cells and the message I want to send.
This is my legend table that will come above my real table, but the configuration is the same in both cases. We’ll have one <TR> block for each line we want to have and as much <TH> lines we need for each cell we want to have. In the end my final table is like this:

As you can see, I send an email with all periods that needs to be restatement showing if the interface already ran, if that was a success, or it had warnings or errors (with the link straight to the error file, if it was not loaded yet and even if we don’t had the partition created for that period/source.
Now, as I said, we need one <TR> per line and, in this case, 16 <TH>, one per cell. As you can imagine, that’s a lot of code that needs to be write there. thanks god I’m using ODI to do that for me, and we’ll take a look on this in the next post.
Thank you guys and see you soon.